

Kafka cheat sheet: Architectural concepts & commands











Kafka cheat sheet
Streaming data platforms help implement applications that require real-time data processing. Real-time event processing applications rely on the durable storage of events, unlike traditional applications that depend only on eventual state storage. Such an architecture helps ensure that application components are decoupled and independently scalable.
Apache Kafka® is an open-source distributed streaming platform. Like any distributed system, Kafka uses a complex architecture and can be overwhelming for a new developer to get started with. Setting it up means dealing with a formidable command line interface and extensive configurations. This article details architectural concepts and frequently used commands that are required for a developer to get started with Kafka.
Key Kafka commands
The Kafka CLI is a powerful tool. However, the user experience can be challenging if you don’t already know the exact command needed for your task. The table below shows commonly used CLI commands to interact with Kafka.
| Create topics | bin/kafka-topics.sh --bootstrap-server <URL> --create --replication-factor 3 --partitions 4 --topic topic-name |
| List all topics | bin/kafka-topics.sh --bootstrap-server <URL> --list |
| Add a topic partition | bin/kafka-topics.sh --bootstrap-server <URL> --alter --topic <topic-name> --partitions 16 |
| Run a producer | bin/kafka-console-producer.sh --topic <topic-name> --broker-list <URL> |
| Run a consumer | bin/kafka-console-consumer.sh --bootstrap-server <URL> --topic <topic-name> |
| Consume messages from the beginning | bin/kafka-console-consumer.sh --topic <topic-name> --bootstrap-server <URL> --group <group-name>--from-beginning |
| Get information on a specific consumer group | bin/kafka-consumer-groups.sh --bootstrap-server <URL> --describe --group <group-name> |
| Delete a consumer group | /bin/kafka-consumer-groups.sh --bootstrap-server <URL> --delete --group my-group --group <group-name> |
| Reset the offset of a topic | bin/kafka-consumer-groups.sh --bootstrap-server <URL> --reset-offsets --group <group-name> --topic <topic-name> --to-earliest |
Understanding Kafka
Kafka can be used as a message broker, a publish-subscribe mechanism, or a stream processing platform. A message broker sits between applications that interact using different protocols and helps in implementing decoupled solutions. A publish-subscribe mechanism helps applications broadcast messages to multiple target applications at the same time asynchronously. Kafka’s stream processing features enable developers to process high-velocity data in an orderly fashion and generate real-time insights.
Kafka is a distributed platform that works based on servers and clients. Organizations can use bare metal hardware, virtual machines, containers, on-premises instances, or cloud instances to deploy Kafka. A Kafka server is a cluster of nodes that can span multiple geographies or data centers. Some of the nodes work as a storage layer, and others work as Kafka Connect instances, which are responsible for managing connections from client applications.
Kafka’s working model contains four key elements:
- Messages are events that get dropped into Kafka for processing.
- Topics are logical groups of messages that signify a specific purpose.
- Producers are client applications that create messages.
- Consumers are client applications that listen to messages in topics and act according to the messages.
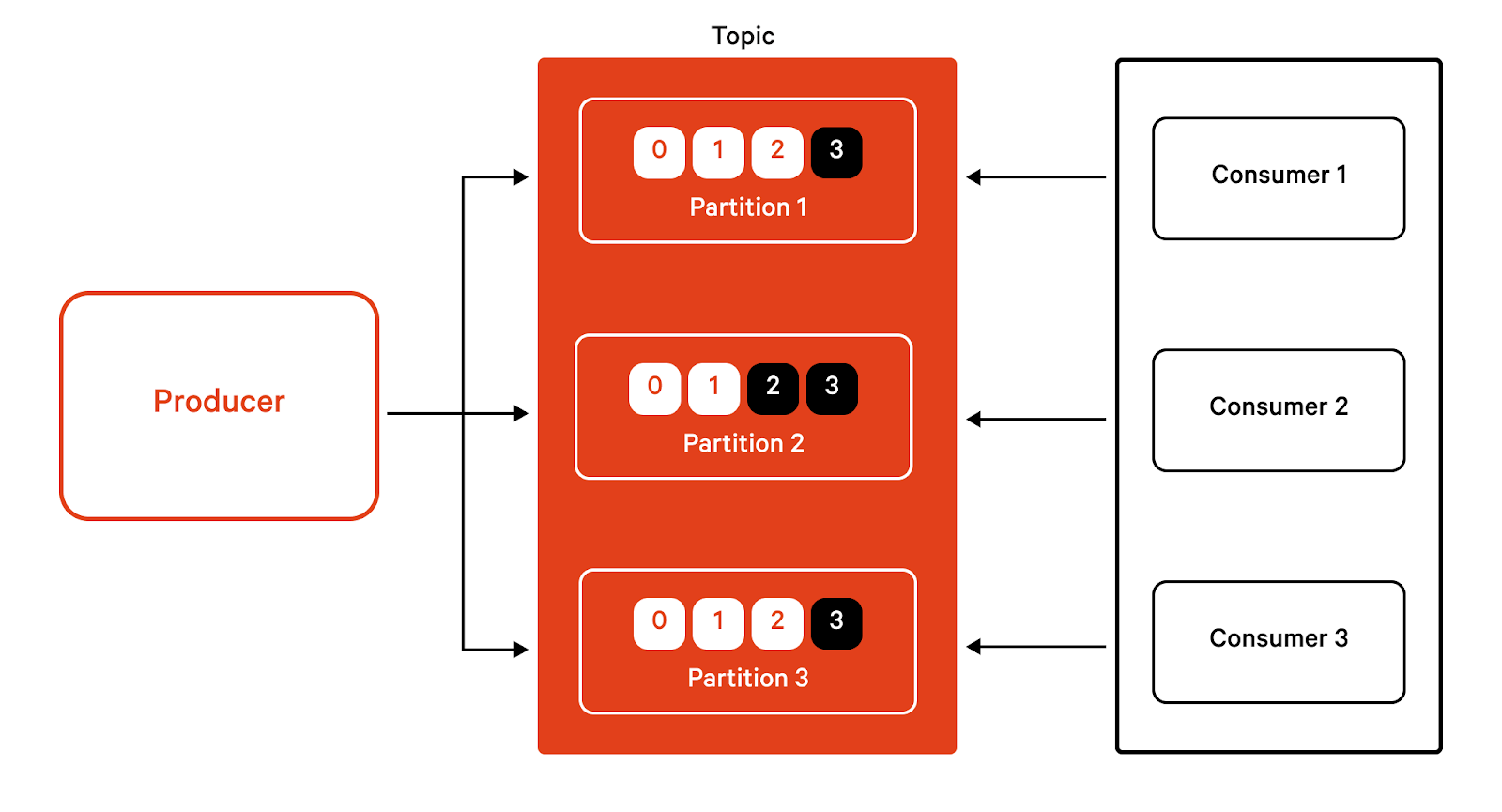
A topic in Kafka is divided into multiple partitions, each of which holds a subset of data. Partitions for the same topic are located in different brokers to ensure distributed data placement. Kafka uses the concept of partitions to provide fault tolerance and scalability for topics.
Kafka topics are logical groups of events or messages intended for a specific purpose that can be from application logs, user activity, device data, etc., depending upon the specific use case. For example, in IoT applications, all messages generated by a specific type of sensor can be sent to a single topic.
Kafka guarantees the preservation of the order of messages within a partition, and scaling client applications is done by using the concept of consumer groups. Kafka ensures that consumers within the same consumer group are not receiving duplicate data through an intelligent assignment of partitions to individual consumers. When an existing consumer leaves a topic or a new consumer joins the topic, Kafka automatically rebalances the partition assignment to ensure a mutually exclusive set of partitions within a consumer group.
Kafka maintains information about the already consumed messages in a partition through the concept of consumer offsets. A consumer offset is simply the count of messages consumed until then by a consumer in a consumer group. Maintaining offsets helps Kafka ensure that consumers can restart at exactly the position where they left off after an unexpected shutdown or rebalance operation.
[CTA_MODULE]
Kafka CLI cheat sheet
The Kafka CLI is an interactive shell environment that lets users manage a Kafka installation and build applications with it. It helps developers manage the running of Kafka topics, connectors, consumers, and producers. This article assumes that you already have a working Kafka installation; if you need to start by installing, Kafka’s official installation page is a good place to begin.
In a nutshell, this CLI is a set of shell scripts that can be used for managing the basic functions of Kafka. The script or command named kafka-topics manages activities related to topics, while the script name kafka-config helps developers configure runtime parameters. Kafka also provides a simple consumer client and producer client.
Creating topics
Developers can create a Kafka topic using a command like the one below.
This command mentions the count of partitions and the replication factor while creating the topic.
Kafka uses the message’s key to decide which partition should be responsible for storing it. If messages do not have a key, they are routed in a round-robin fashion so that all partitions take on a uniform load.
The replication factor in Kafka represents the number of duplicate copies of partitions that are kept among different nodes. Replication in Kafka is done at the partition level, and Kafka recommends keeping the replication factor above 1 to ensure high availability.
Listing topics
You can use a command like this one to list the topics that already exist in the Kafka server:
If you are using a version of Kafka with Zookeeper, you can pass the parameter –zookeeper and your ZooKeeper URL to get the list.
Describing topics
Kafka lets developers access the details of the topic through the describe command, as follows:
The topic description provides information on the number of partitions, replication factor, leader parameter value, replicas, and in-sync replicas. The number of partitions and replication factors are self-explanatory. The value of the leader parameter represents the node that acts as the leader for that topic. The replicas parameter value shows the nodes that hold duplicates of the partitions. The in-sync replica or ISR represents the nodes that are caught up with the leader and hold an exact duplicate of the data in the leader node. This is the minimum number of replicas that Kafka must ensure to mark a transaction as committed.
[CTA_MODULE]
Adding partitions to a topic
Developers often need to scale Kafka topics after they are created. Kafka provides the alter command to add more partitions to existing topics:
Changing the retention period for a topic
By default, Kafka retains all messages for seven days. Depending on the requirements, developers may want to increase or decrease this value. Increasing the retention period helps with keeping more history in memory at the cost of storage. Changing the retention period can be done as follows:
Deleting a Kafka topic
Deleting a topic in Kafka is not an immediate process: Once the delete command is issued, the console output will show that the topic is marked for deletion. The timing of the actual deletion will depend upon many factors, including the availability of a leader node for that topic, configured retention policies, etc. The deletion operation can be triggered using a command like this one:
Publishing events to a topic
Kafka producers publish events to the durable queue provided by Kafka. Kafka producers can control the partitions to which data is written and the level of acknowledgment required to mark a write as successful. This example uses the console producer that comes built-in with Kafka to publish messages to a topic:
The command above provides a prompt where you can enter the messages for publishing. After typing the message, you can press the Enter key to submit it and type the message.
Kafka producers provide numerous configurations that can control the durability and throughput of published messages. The acks parameter that controls the level of acknowledgment is an important one. Each Kafka partition has a leader node and a replica node; when the value of acks is 1, only the acknowledgment from the leader node is sufficient to mark a write as successful. If the value is set to all, acknowledgment from all the nodes marked as in-syn-replicas is necessary.
Consuming messages from topics
Kafka consumers are client applications that listen to the Kafka server and act on the messages. The simplest Kafka consumer is the console consumer that comes built-in with Kafka, which prints the received messages in the console. It can be used as shown below.
Kafka uses the concept of consumer groups to scale message consumption. Consumers belonging to the same consumer group are assigned to different partitions by default. This ensures that messages already consumed by a consumer are not assigned to another one, which would lead to duplicates.
Kafka consumers often execute high-latency tasks like database writes or complex message transformations. A single consumer may not always be able to keep up with the rate at which producers publish data; consumer groups help avoid this situation.
Consuming messages from the beginning
By default, Kafka consumers start from the last offset when they are restarted. There are cases where developers may want to start from the beginning upon restarting a consumer, which can be achieved using the command below:
Listing consumer groups
To list all the consumer groups in a server, use a command like this one:
Describing consumer groups
Describing consumer groups helps developers get information on partitions, the current offset in each partition, etc. This information is helpful for debugging Kafka issues and deciding whether to reset the offsets. Developers can use the command below to describe consumer groups:
Deleting a consumer group
Manually deleting a consumer group can be done using this command:
Resetting offsets for topics
Offsets help Kafka manage consumer failures and restarts. Offsets are simply the count of the messages consumed until a specific point. Keeping offsets helps consumers restart consumption gracefully without duplicates. At times, developers may want a consumer group to process the whole partition irrespective of consumption status, which can be done by resetting the offset. The command for resetting the offset and starting from the earliest message is as shown below:
[CTA_MODULE]
Conclusion
Kafka’s command line interface is powerful, but it helps to have a cheat sheet on hand. Everyone occasionally forgets which command to use in a certain situation. We hope that this article can serve as a reference for you when you need to brush up on different commands available for administering Kafka.
[CTA_MODULE]