

RabbitMQ vs. Kafka—Understanding the differences











RabbitMQ vs. Kafka
RabbitMQ and Apache Kafka® are great tools for asynchronous message processing when planning an application's architecture. Although both RabbitMQ and Apache Kafka are open-source, asynchronous applications with similar message brokering capabilities are not interchangeable. Making a decision between RabbitMQ vs. Kafka requires understanding which tool is right for a given application.
This article will use code samples, diagrams, and in-depth explanations to compare RabbitMQ vs. Kafka.
Summary of key differences in RabbitMQ vs. Kafka
Because these open-source message-handling solutions are widely used, choosing between Apache Kafka and RabbitMQ takes a lot of work.
In a nutshell, Kafka's queue is permanent, unlike other message systems. This means that data supplied to Kafka is retained until either a time restriction or a size limit is met. On the other hand, RabbitMQ holds messages until a receiving application connects to the queue and reads them. The client can acknowledge the message at that moment or after the processing is finished. Either way, in the default configuration for RabbitMQ, the message is removed from the queue once it is acknowledged.
The table below summarizes the key RabbitMQ vs. Kafka differences to help you make an informed decision.
| Attribute | Apache Kafka | RabbitMQ |
|---|---|---|
| Founded | The first version was released in 2011 | The first version was released in 2007 |
| Developed By | Apache Software Foundation | Pivotal Software |
| Implementation Language | Java and Scala | Erlang |
| Open Source License | Apache License 2.0 | Mozilla Public License |
| Types | Stream processing and message broker | AMQP, message-oriented middleware |
| Approach | Broker waits for the consumer to request/pull the data | Messages are immediately pushed to any subscribed model |
| Performance | 1 million messages per second | 4K-10K messages per second |
| Message Retention | Policy-based message retention | Acknowledgement-based message retention |
| Message Ordering | Message ordering is provided through its partitioning | Message ordering is not supported |
| Message Priority | Not supported | Users can specify the message priorities and consume messages based on those priorities |
| Broker/ Consumer Model | Kafka has a dumb broker and a smart consumer | RabbitMQ has a smart broker and a dumb consumer |
| Data Format | Binary - Any data format using the Serializer and Deserializer | STOMP, MQTT, AMQP, JSON, XML, Custom |
| Data Type | Operational data type | Transactional data type |
| Topology | Kafka uses a publish/subscribe topology | RabbitMQ uses an exchange type topology that includes direct, fanout, topic, and header |
| Max Payload Size | Kafka has a default max payload size of 1MB. | RabbitMQ has zero constraints in payload size. |
| Authentication | Kafka supports Kerberos, OAuth2, and standard authentication. | RabbitMQ supports standard authentication and OAuth2. |
| Monitoring | Monitoring is available through third-party tools, such as when deployed on Redpanda. | Monitoring is available through a built-in UI. |
| Use Cases | Kafka can be used in high throughput use cases, analysis, tracking, ingestion, logging, and real-time processing. Ideal use cases are: complex routing, event sourcing. | RabbitMQ is typically used in low-latency use cases, long-running tasks, and application integrations. Ideal use cases are those that require quick response times or the use of legacy protocols. |
| Delayed Messaging | Kafka does not support delayed messaging. | RabbitMQ has a plugin called "Delayed Message Exchange" that enables delayed messaging by holding the message for a specified time before routing it to a queue. |
| Scheduled Messaging | Kafka does not have built-in support for message scheduling. | RabbitMQ allows for scheduled messaging through the "Message Timestamp" plugin, which enables messages to be sent with a designated timestamp for later delivery. |
What is RabbitMQ?
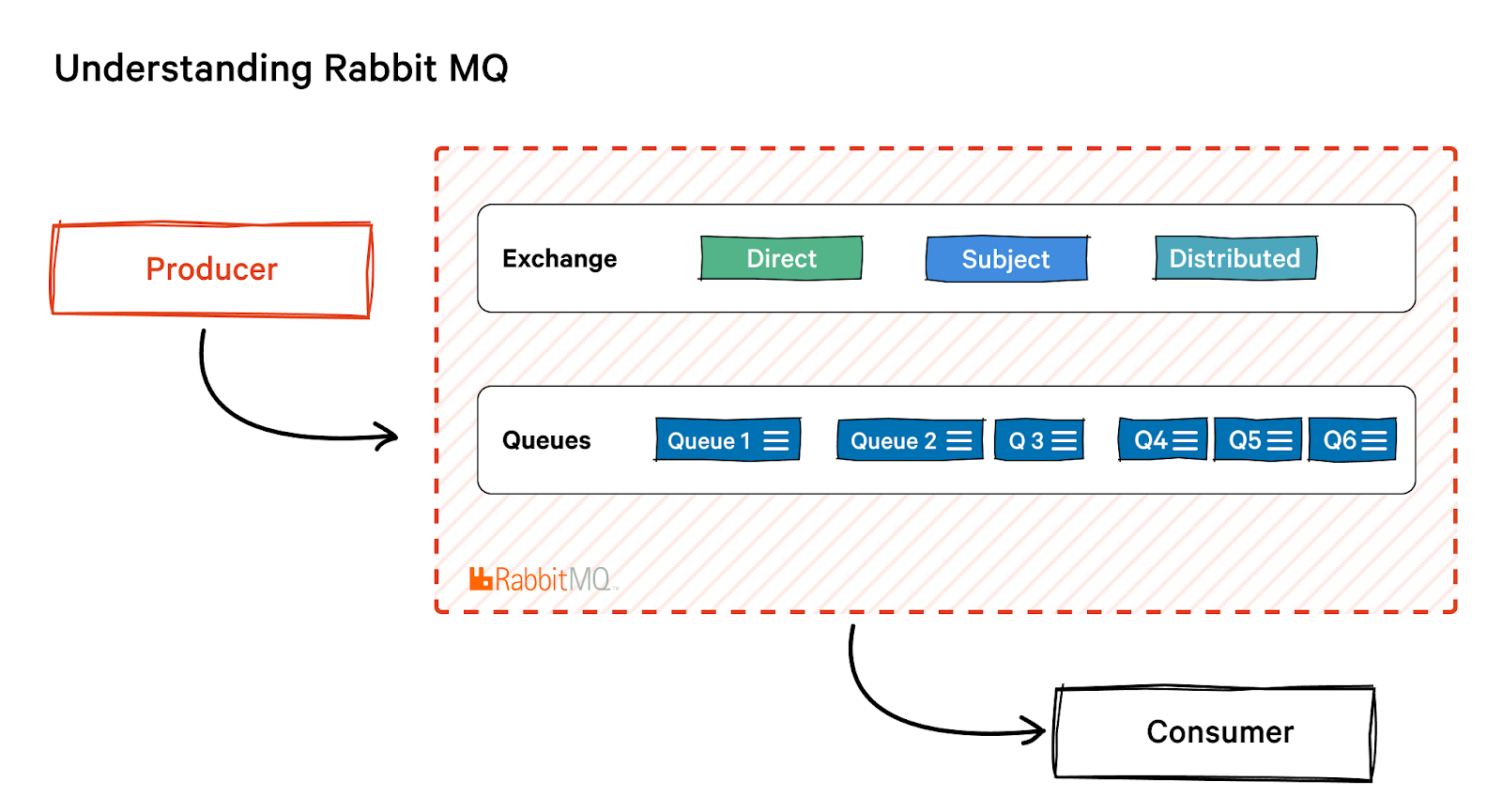
RabbitMQ is an open-source, distributed message broker and queueing platform written in Erlang or Open Telecom Platform (OTP) language. That allows high availability and fault tolerance. The term "distributed" refers to the fact that RabbitMQ is often deployed as a cluster of nodes, with queues dispersed across the nodes — duplicated for high availability and fault tolerance.
RabbitMQ uses a push mechanism and prevents overloading users by using a consumer-configured prefetch limit. This paradigm is suited for low-latency communications. It also goes great with the queue-based RabbitMQ architecture. You can think of RabbitMQ as a post office that receives, stores, and distributes mail, whereas RabbitMQ accepts, stores, and sends binary data messages.
Key features of RabbitMQ
RabbitMQ is a robust and reliable message broker. Key RabbitMQ features include:
- Inbuilt clustering with RabbitMQ: RabbitMQ's clustering allows consumers and producers to continue functioning if one node fails and to scale messaging throughput linearly with additional nodes in the event of a node failure.
- Routing flexibility: RabbitMQ offers several exchange types with built-in routing capabilities. It is typical for messages to be routed through exchanges before reaching queues in a typical routing scenario. Users can bind exchanges together or write their exchange types as plugins for complex routing.
- Reliability: RabbitMQ can persist messages on disk to ensure messages are not lost incase of broker failure, and can survive a broker restart. It also has a mechanism where the publisher knows if the message has been successfully received by the consumer.
- Security: RabbitMQ provides multiple levels of security. It enforces SSL-only communication and Client Certificate Checking, which helps secure client connections.
What is Kafka?
Kafka is an open-source, distributed event streaming platform written in Java and Scala that allows raw throughput. The Kafka message bus is a pub/sub (publish/subscribe) messaging system aimed at streams and data replay. Instead of using a message queue, Kafka is a distributed commit log-based system that writes messages to a topic, where they stay until they are read by the consumer or their retention period expires.
It implements a producer-consumer pattern which ensures that producers write and store messages in the Kafka cluster and independently the consumer requests and retrieves data from the cluster. Messages can be processed individually or in batches and are-consumed multiple times.
[CTA_MODULE]
Key features of Apache Kafka
Apache Kafka offers message communication and stream processing for real-time data storage and analysis. Key Kafka features include:
- Persistence by default: Durability is achieved by persisting the produced data immediately and does not suffer performance degradation as the persisted data accumulates.
- High throughput: Kafka was built to handle massive volumes of data and can accommodate millions of messages per second.
- Distributed event streaming platform: Apache Kafka is a distributed event streaming technology that allows you to partition messages among Kafka brokers and distribute consumption over a group of consumers while guaranteeing per-partition ordering semantics.
- Real-time solutions: Messages generated by producers are available to consume immediately
Understanding the differences between RabbitMQ vs. Kafka
The sections below explore the key differences between RabbitMQ vs. Kafka in detail.
RabbitMQ vs. Kafka: Architecture
RabbitMQ is a message broker based on a traditional messaging model known for its flexibility and ease of use. RabbitMQ messaging flows like this:
Consumer -> Exchange -> Binding Rules -> Queue -> Producer
Kafka is a distributed streaming platform based on a publish-subscribe with a persistence model designed to handle large amounts of data. Kafka messaging flows like this:
Consumer -> Broker -> Partition -> Consumer
RabbitMQ vs. Kafka: Push vs. pull model
RabbitMQ implements a "push" messaging model, where messages are produced by senders and consumed by receivers. The messages are sent to queues and consumed by receivers in the order they were produced. Producers can send messages to multiple queues, while receivers can consume from multiple queues. In this model, messages are pushed to the queues by the producers, and the consumers pull them from the queues as they become ready for processing.
Kafka messages are produced by one or more producers and consumed by one or more consumers. Producers write messages to topics, and consumers read from those topics. The messages are stored in a distributed log and persist for a configurable amount of time, allowing consumers to read them at their own pace. This is called a "pull" model, as consumers pull messages from the topic as they are ready to process them.
[CTA_MODULE]
RabbitMQ vs. Kafka: Message routing
RabbitMQ uses a traditional message broker to handle message queues and routing. It supports a variety of messaging patterns, such as publish-subscribe and request-response, and allows for flexible routing of messages based on routing keys, topics, and other criteria. It also offers a variety of built-in routing mechanisms, such as direct, topic, and fanout exchanges.
Kafka uses a partitioned and replicated log system for message storage. It supports a publish-subscribe model, where messages are written to topics, which are logical groupings of partitions, and consumers subscribe to them to receive messages. The messages are replicated across multiple brokers, and consumers can read from a specific partition or multiple partitions, depending on their needs.
RabbitMQ vs. Kafka: Delivery guarantees
RabbitMQ also provides "at-least-once" delivery guarantees, meaning that messages will be delivered at least once, but may be delivered multiple times in the event of failures. It achieves this by acknowledging receipt of messages by consumers and re-queuing messages that have yet to be acknowledged. Additionally, RabbitMQ supports the persistence of messages to disk, ensuring that messages are not lost in case of a broker failure.
Kafka also provides "at-least-once" delivery guarantees but uses a different mechanism to achieve them. By committing the offset of a message, the message is considered delivered and this offset commit is bookmarked on the consumer client side as well as on the broker side. The consumers can choose to re-consume the messages by changing their start offset and in some cases if there are failures or rebalances on the consumers there can be differences in the logical offsets, therefore reconsumption can occur.
Writing code for RabbitMQ vs. Kafka
Here is a simple Python script that sends a message to a RabbitMQ queue and receives the message from the queue.
Compare that to this Python script that produces a message to a Kafka topic and consumes the message from the topic.
RabbitMQ is often useful in use cases that require a lower latency inter-process communication between microservices or applications. For example, potential RabbitMQ use cases include:
- Building a decoupled architecture where different microservices can communicate asynchronously through RabbitMQ, allows more flexibility, scalability, and fault tolerance.
- Implementing a message-based communication pattern, such as publish-subscribe, to distribute messages to multiple consumers. This can be used to create real-time notifications, for example, or to distribute tasks to a worker queue for background processing.
- Implementing a request-response pattern to handle synchronous communication between microservices, for example, to handle API calls.
Overall, RabbitMQ is well-suited for transactional microservices or applications and can support a variety of messaging patterns.
Use cases for Kafka
Kafka use cases generally focus on real-time data streaming and processing. For example, potential Kafka use cases include:
- Building a real-time data lake to store and process a large amount of data and make it available for real-time analytics
- Collecting and analyzing data from IoT devices or mobile apps in real time.
- Processing and analyzing social media or website data in real-time for monitoring brand mentions, sentiment analysis, or other marketing insights.
- Building a real-time data pipeline to ingest, process and analyze data from multiple sources in real-time, such as from databases, logs, or other systems.
- Building a messaging system that can handle high volumes of data with higher durability, for example, for financial transactions or e-commerce systems.
Overall, Kafka is well suited for building real-time data pipelines and streaming applications that handle high volumes of data with high durability and fault tolerance.
RabbitMQ vs. Kafka: Key points to consider when making a decision
When choosing between RabbitMQ and Kafka, it is essential to consider your use case's specific requirements and avoid common mistakes. Here are a few tips to help you make the right choice:
- Understand the differences between RabbitMQ and Kafka. RabbitMQ is a message broker that supports various messaging protocols and patterns. At the same time, Kafka is a distributed streaming platform optimized for handling high volumes of data with higher durability and fault tolerance with reasonable latency. Make sure you understand the key differences between these two technologies and choose the best suited for your use case.
- Don’t underestimate the complexity of distributed systems. Both RabbitMQ and Kafka are designed to work in distributed environments, but this also means they can be more complex to set up, configure, and maintain. Make sure you have the necessary expertise and resources to manage and operate these systems.
- Consider scalability and performance. Both RabbitMQ and Kafka can handle large volumes of data, but they have different scalability and performance characteristics. Make sure to consider the specific requirements of your use case and choose a solution that can meet your performance and scalability needs.
- Pay attention to security. Both RabbitMQ and Kafka can be configured to support various levels of security, such as authentication, authorization, and encryption. Make sure to consider your security requirements and choose a solution.
[CTA_MODULE]
Conclusion
There’s no single right answer when it comes to RabbitMQ vs. Kafka. However, keeping these key points in mind can help enterprises make the right decision for their use case:
- RabbitMQ is well-suited for message queuing and routing, work queues, and interoperability with other messaging systems or applications due to its support for various messaging patterns and protocols, work queue capabilities, and multiple API support.
- Kafka's strength lies in its ability to handle large volumes of data and process real-time data streams efficiently. It is commonly used in use cases such as log processing, data streaming, and real-time analytics. Kafka is also well-suited for event-driven architectures and microservices, where it can handle high-volume event data and deliver events reliably to consumers. Its distributed architecture and fault-tolerant design make it a solid choice for building large-scale distributed systems.
Both RabbitMQ and Kafka have unique advantages and limitations and the choice between them must be based on the specific needs of the use case.
[CTA_MODULE]