

Kafka schema registry—Tutorial & best practices











Kafka schema registry
Messages sent to an Apache Kafka® cluster can adhere to whatever format the producer chooses. From Kafka’s perspective, a message is just a byte array. This can lead to deserialization issues when a data topic’s format changes. Every time you change the schema for some messages, you must inform every related consumer and producer.
Kafka schema registry addresses this problem by allowing records to specify their own format. This format specification is a schema. Kafka stores these schemas in a central registry, which consumers and producers can access to find out what schema a given message follows.
Additionally, the Kafka schema registry checks whether messages in a topic adhere to the schema to prevent run-time failures in applications that expect a specific message format. A schema registry makes transferring messages robust and compliant in Kafka.
This article will show you how the Kafka schema registry works, teach you how to use it, and review best practices.
Kafka schema registry: summary of key concepts
Let’s start with a quick overview of the Kafka schema registry topics we’ll review in this article.
| Topic | Description |
|---|---|
| When to use Kafka schema registry | When the schema is expected to change and adhere to one of the serialization formats supported by Kafka. |
| When not to use Kafka schema registry | When the schema is fixed and won’t require a future change. |
| Serialization format | Kafka Schema Registry supports a few different serialization formats, but Avro is recommended for most use cases. |
| Compatibility mode | Allow a schema to work for consumers and producers who expect a newer or older version of the schema. |
| Optimal configuration | Assign default values to fields you might remove, do not rename an existing field (add an alias instead), and never delete a required field. |
How Kafka schema registry works
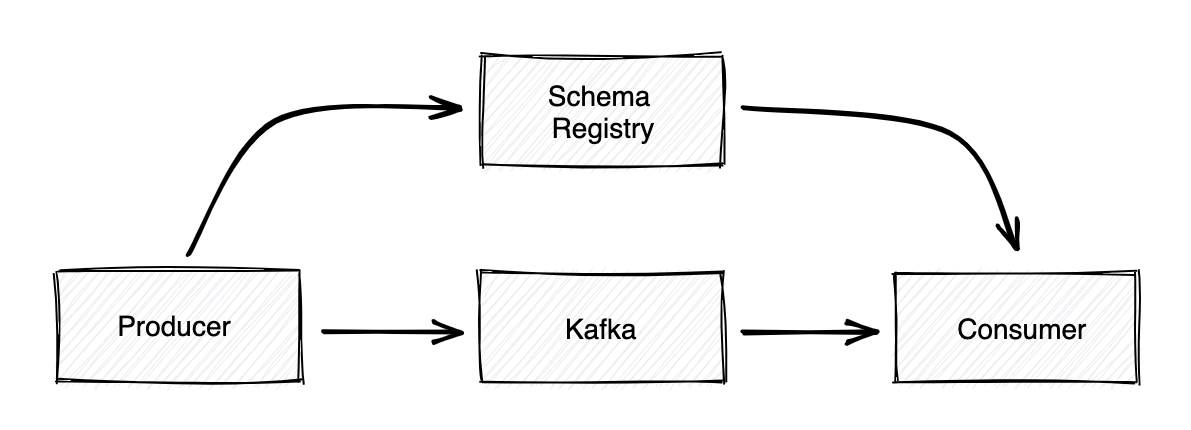
A Kafka schema registry resides in a Kafka cluster. It can be plugged into the Kafka configuration. The configuration stores the schema and distributes it to the producer and consumer for serialization and deserialization. Hosting schemas like this allows schema evolution, making message transfer robust.
Without schemas, there would be no easy way to establish a contract ensuring messages sent by the producer match the format expected by the consumer.
The schema registry maintains a history of schemas and supports a schema evolution strategy. With a schema registry, you can plan how future applications will maintain compatibility with a certain schema even if you add or remove fields later.
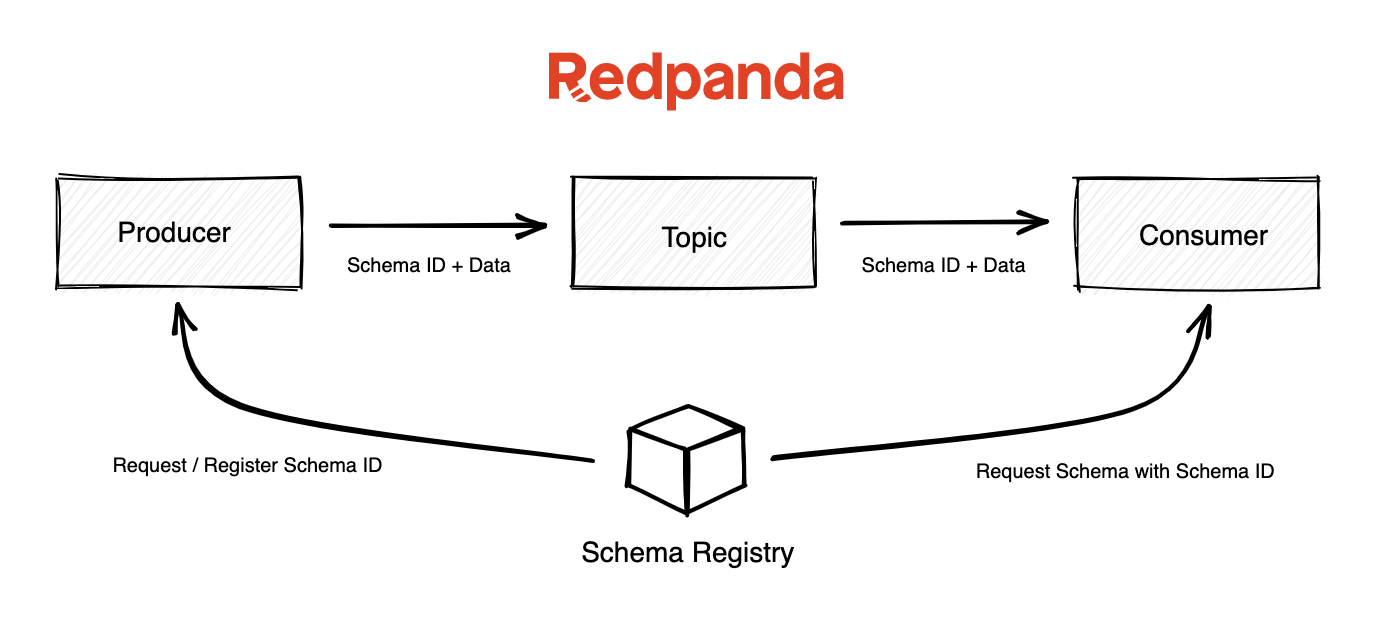
When publishing a record, the producer checks if the schema is already registered in the schema registry and pulls up the Schema ID. It then serializes the data with the schema and sends the unique Schema ID and the data. It registers and caches it by default if it’s not registered with the schema registry.
On the consumer side, Kafka will consult the schema registry using the Schema ID supplied by the producer to deserialize this message. If there is a schema mismatch, the producer will be immediately identified for violating the implicit contract.
[CTA_MODULE]
How to use the schema registry
To register a schema, send a POST request to the schema registry service endpoint http://localhost:8081/subjects/order-value/versions with the header Content-Type: application/vnd.schemaregistry.v1+json and supply the schema itself in the request body.
To create a Java class out of the schema, use the Avro compiler plugin to generate a Java Model class which the producer can use to write data to the topic. Make sure to add the corresponding dependency to the project.
Now we can build the project.
Once the project is built, you can use the new instance of the generated POJO class to send an order instance to the order topic, as illustrated below.
Let’s start with the code for the producer.
Now that we can send records, we need a consumer to receive them.
However, there is a possibility that the business requirements may change and you’ll need to change the schema. Let’s say the business decides to add the customer_id along with the order_id for real-time analytics. What happens when we add a new field in the schema and try to register it in the schema registry?
By default, the schema registry checks for backward compatibility, meaning the newer schema can also read data written with the older schema. Backward compatibility allows the consumer of the newer version to read messages with the previous schema.
Let’s try to register a new schema. Once again, we need to send a POST request to the same schema registry service endpoint we used to register the previous schema.
When we send this request, we receive a JSON response.
We see this error because the consumer expects a value for customer_id based on an older schema. To make it compatible, add a default value for customer_id
Now we get the expected response.
Once we register this new schema, it'll be successfully registered with a new version and a unique Schema ID, “3” in this case. Also note that although the updated Schema ID may not be incremented sequentially, the version sequentially incremented to “2”.
[CTA_MODULE]
Kafka schema registry best practices
Now that you know how the Kafka schema registry works, let’s look at how to use it optimally and configure it appropriately for your use case.
Choose the right compatibility mode
There are four compatibility modes in schema evolution.
- Backward compatibility
- Forward compatibility
- Full compatibility – a combination of backward and forward compatibility
- None – does not ensure any compatibility
You can set the Kafka schema registry compatibility mode by sending a PUT request to the schema registry service endpoint http://localhost:8081/config/order-value/ with the Content-Type header set to application/vnd.schemaregistry.v1+json. The body of the request should specify the mode you want to set, for example {"compatibility": "FORWARD"}.
How to set a Kafka schema registry compatibility mode
Let’s go through each so you can know when to use it.
In a forward-compatible change, consumers who adhere to the previous schema can consume records that adhere to the current version. Forward compatibility is optimal when you have consumers that might still use the older schema version for some time. To demonstrate this, let’s say we rename the item_name to product_name in the newer schema.
if forward compatibility mode is active, the older schema won’t get the value of the item_name, and the schema will fail to register. The solution in this case is to add an alias. The alias clarifies that product_name and item_name refer to the same thing.
On the other hand, a backward-compatible change means that consumers adhering to the current schema can consume messages produced in the previous version. This compatibility mode is ideal when you have producers that might delay updating to the newest schema version.
You can deploy a full-compatible change if you want the best of both worlds. In this scenario, a schema version is both backward and forward-compatible.
Finally, you can create a version of a schema that offers no compatibility assurances whatsoever. This has the benefit of being the most straightforward form of compatibility to implement.
You can learn more about evolution strategy by following the advice in this article: Practical Schema Evolution with Avro.
Kafka schema registry configuration tips
Here are four tips for Kafka Schema Registry configuration that can go a long way in preventing problems later on.
- Assign a default value to the fields that you might remove in the future
- Do not rename an existing field—add an alias instead
- When using schema evolution, always provide a default value
- When using schema evolution, never delete a required field
Most of those tips apply primarily to producers. You can learn more about configuring consumers in our companion article: Kafka Consumer Config.
Registering schemas in production
As we demonstrated earlier, you can automatically register a schema by simply sending a message that follows a given schema. In production, you don’t want to be so ad hoc. Instead, you should register schemas beforehand.
You can disable the auto-schema registry by setting up auto.register.schemas=false in the producer configuration.
When to use Kafka schema registry
How do you know if the schema registry is the right tool for the kind of data you manage with Kafka?
This decision is simple. It's probably the right choice if you meet the following criteria:
- The schema is likely to change in the future
- When schema is expected to change in the future
- The data can be serialized with the formats supported by Kafka schema registry
When not to use Kafka schema registry
Despite the benefits offered by the Kafka schema registry, there are situations in which it’s not the right choice. After all, the schema registry incurs development overhead. If that overhead is not justified, it’s best not to use the schema registry. Examples of when not to use Kafka schema registry include:
- You’re certain the schema won’t change in the future
- If hardware resources are limited and low latency is critical, Kafka schema registry may impact performance (e.g., for IoT)
- You want to serialize the data with an unsupported serialization scheme
Choosing a serialization format for Kafka schema registry
The Kafka schema registry supports three serialization formats:
- Avro (recommended for most use cases)
- JSON
- Google Protobuf
There is no right or wrong answer, but here are a few things to consider when choosing the right one for your use case:
Avro is flexible due to its support for dynamic typing. It does not require regenerating and recompiling code with every schema update, although doing so can optimize performance.
One of Avro's strengths lies in its ecosystem, especially around languages like Java, where it offers extensive libraries and tools that integrate seamlessly with Java applications.
Another advantage of Avro is its human-readable schema format, which significantly aids in debugging and maintaining the codebase by making it easier to understand the data structures in use. Avro supports native Remote Procedure Call (RPC) mechanisms, enabling efficient and direct communication between different components in a distributed system without needing an additional layer for RPC handling.
Protobuf is optimized for high performance, using a binary encoding that omits the schema within the serialized data. This approach minimizes the data payload size if your bandwidth is limited. Protobuf's binary format is less readable, but it supports a broader range of programming languages, offering a more versatile solution for multi-language environments.
It's worth noting that while Protobuf supports more languages, the level of tooling and ecosystem support may vary. A significant feature of Protobuf is its native support for gRPC, an integration that allows for easy implementation of efficient, scalable microservices.
JSON has the advantage of being a human-readable, non-binary format. However, it comes with negative performance impacts because JSON is not compact.
[CTA_MODULE]
Conclusion
The Kafka schema registry is helpful when a message schema is expected to evolve and should be bound by a contract so that the message being sent by the producer and the consumer is in the correct format expected. It’s a simple yet powerful tool for enforcing data governance in the Kafka cluster.
[CTA_MODULE]