

Kafka console producer: Tutorial & examples











Kafka console producer
Kafka allows you to use the command-line to manually create producers. Although producers and consumers typically interact with Kafka through code, there are some special cases when manually producing records on a topic is useful. For example, when backfilling missing data, or simply testing to make sure your setup is working correctly.
In this article, we’ll help you understand how and when to use the kafka-console-producer command-line interface (CLI) to produce data for a topic and give you step-by-step instructions for doing so. Finally, we’ll give you recommendations for when the console producer is the best tool, along with tips and best practices to use it optimally.
Summary of use cases
For a quick reference before we dive into the full guide, here are the primary uses for the Kafka console producer, compared to conventional producers that use code libraries to communicate with Kafka.
| Use Case | Explanation |
|---|---|
| Testing | Make sure you can send data to the Kafka cluster successfully. |
| Backfill data | Import data externally, for example, old data stored in a CSV (comma-separated values) file. |
| Shell script | The Kafka console makes it easy to produce messages on a topic from a shell scripting language like Bash. |
How Kafka console producer works
A producer in Kafka sends data to the Kafka cluster for a specific topic. In turn, consumers subscribe to a topic and process the messages independent from other consumers. Typically, a producer is an application, but the Kafka Console Producer allows you to manually produce data to a topic at the command-line.
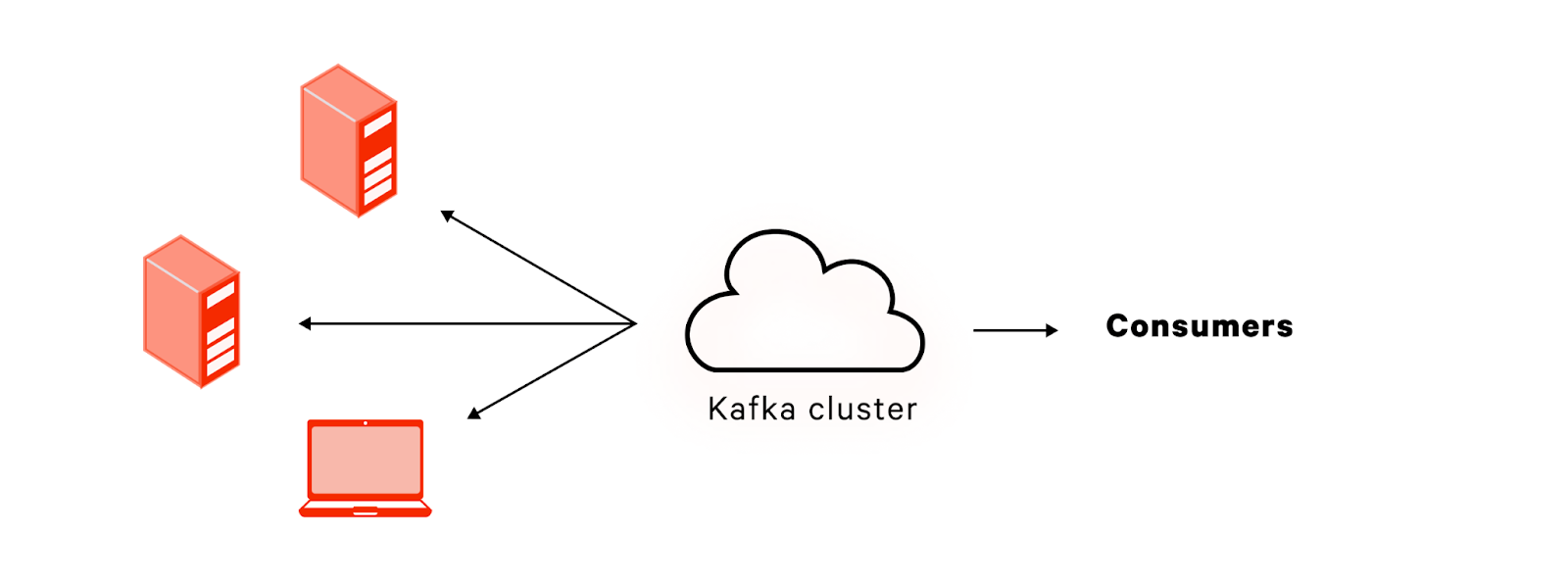
How to use Kafka console producer
First, we’ll need to set up Kafka and create a topic. For these examples, I will use a MacOS. To receive instructions for installing Kafka on Ubuntu, consult our article on Kafka itself.
Let’s begin installing Kafka.
Before we can start Kafka, we need Zookeeper to be running. Kafka uses Zookeeper to track internal state (and other low-level plumbing we don’t need to worry about here), although newer versions of Kafka are making it possible to use Kafka without Zookeeper. Additionally, modern alternatives to Kafka like Redpanda already work well without Zookeeper.
We’ll start Zookeeper using the default configuration provided upon install
you’ll know it worked if you see a cool ASCII art in your terminal that looks like this:
With that boilerplate out of the way, we can start Kafka itself!
When we send data to Kafka, we need to produce it to a specific topic. The consumer, in turn, will subscribe to that topic. Let’s create an example topic called example-topic that our console producer can send information to.
Finally, we can use the Kafka CLI to manually produce on a topic!
Running the command gives us a prompt where we can enter the data we want to send. To exit the prompt, enter Control+C.
So that’s how we manually produce data on a topic. Why would we want to do this? Let’s explore some use cases that demonstrate the usefulness of the Kafka console producer!
Use cases for Kafka console producer
Now that we’ve covered the theory behind how the Kafka console producer works and given a simplistic example of connecting and sending some data, we should go deeper and demonstrate the Kafka console producer in the context of its real-world uses.
Testing
Often you want to play with a Kafka cluster in a more hands-on way for either one of two reasons:
- You have deployed a new cluster and want to try it out
- You are debugging an issue with an existing cluster.
Writing a test application just to send messages to the cluster and display the results would be tedious. It’s much easier to hop on the terminal and see what’s going on interactively. Let’s imagine you have deployed an Apache cluster and are using Avro to serialize data and lighten network overhead. How can we check that our Avro setup works as expected?
First, let’s send the message using the Kafka console Avro producer.
Now we can use the accompanying tool, the Kafka console Avro consumer, to verify that the message made it through.
Thus we can verify that our setup is working. Thankfully, the Kafka CLI makes even serialization easy enough that we can do it manually in a quick interactive session. Note that not every distribution of the Kafka command-line tools includes the Avro console toolset. If you are missing these commands, you can download them here: https://www.confluent.io/get-started/?product=software
Backfill data
Let’s say you have a backlog of orders for a product that should have gone to a topic called orders. However, a batch of orders didn’t make it to the topic’s consumers. You have the missing orders as a CSV file called backorders.csv that looks like this:
This goes on for several hundred lines. Manually entering it into the console producer would be too tedious. Nevertheless, you’d still prefer to avoid the inconvenience of writing a script in a formal programming language just to load this one file.
Kafka console producer solves this for us by allowing us to easily load data from a file. First, since this CSV file has a header line at the top, we’ll have to remove that before loading the data into Kafka.
Now that we have prepared the data, we can load it into the console producer.
Done! As seen above, effective Kafka administration from the console occasionally requires basic knowledge of the command line. You can learn more about the command line for your operating system using the resources below:
- Windows: https://learn.microsoft.com/en-us/powershell/
- Linux: https://ubuntu.com/tutorials/command-line-for-beginners
- MacOS: https://support.apple.com/guide/terminal/welcome/mac
Shell script
As we mention throughout this article, the console is not the typical way that to produce messages to topics in Kafka. Usually, a program sends the data using a library available for that programming language. However, if you’re writing a shell script, the console producer can be the most convenient way to produce a message programmatically.
For example, you could create a daemon that checks a log file every minute for security events using a simple Bash script
This makes it easy to use Kafka within a shell script, without needing to resort to a conventional programming language.
Recommendations
Understanding how the Kafka console producer works and what to use it for is just the beginning. The actual complexity comes when you need to know when to use a given tool in high-pressure production environments. Let’s go through some tips and best practices for using these tools in the field.
Dealing with encoded messages
When working with encoded messages, the consumer must use the same schema when decoding a message that the producer used when encoding it. This could lead to difficulties in coordinating which schema was used for a given message.
To solve this problem, Kafka offers the Schema Registry, which allows you to specify the schema used to identify which schema was used for a message. The producer embeds a schema ID into the message itself, which the consumer can then look up in the registry and retrieve the exact scheme.

Working in production
Sending data to a topic from the command line is risky business. One typo can send data to a topic irreversibly. This risk is even more severe when working with production systems, where a listening consumer can spring into action and launch a whole plethora of reactions to an event.
We recommend not using the Kafka console to produce data manually in production unless you absolutely must. Be extremely cautious when dealing with production systems via the Kafka console producer. Double-check everything and carefully verify that you’ve formatted the message precisely according to the specification.
The Kafka CLI ecosystem
Producers are not the only component of Kafka that has a rich console experience. Kafka’s CLI makes it easy to interact with Kafka via the terminal. Earlier in this article, we gave you a taste of setting up a consumer through the console. In reality, the console consumer has different use cases and best practices. In our companion guide, Kafka Console Consumer, learn more about Kafka console consumers.
[CTA_MODULE]
Conclusion
Kafka makes it easy to decouple the sources that produce data from the applications that consume it. Typically, applications produce data programmatically. Sometimes, though, engineers need to produce data on a topic manually. Whether backfilling old data or just testing something out, the Kafka console producer makes it easy to act as a producer manually. We hope the guide above has helped you understand what the Kafka console producer does and how to use it properly.
[CTA_MODULE]