

Kafka without Zookeeper—Tutorial & examples











Kafka without ZooKeeper
People have been using Apache ZooKeeper and Apache Kafka together for years. However, recent features have made it possible to run Kafka without ZooKeeper. What has changed since the release of Apache Kafka 3.3? What tooling came in with the latest releases, and how should you use kafka-metadata-quorum and kafka-metadata-shell? In this article, we aim to answer these and other pertinent questions.
Historical background and timeline
Long ago, Apache Kafka server was a standalone service: a simple and functional application that quickly became loved by many. However, it lacked high availability and resiliency. The standard way for a system administrator to solve that issue was often to create multiple broker copies for replication purposes, coordinated by well-known technology — Apache ZooKeeper — which quickly became a part of a standard Kafka deployment, the two working together in symbiosis.
Nevertheless, Apache ZooKeeper is not a silver bullet. Apache Kafka technology resilience, scalability, and performance expectations have evolved over time, leading to more demanding requirements. There were lots of changes made, the most significant being consumer offsets migration from ZooKeeper to Kafka, the gradual removal of ZooKeeper connection hosts in Kafka tooling, and implementation of the famous KIP-500 (Kafka Improvement Proposal 500).
KIP-500 appeared starting in version 2.8, when Kafka Raft (KRaft, a consensus protocol Raft implementation for Apache Kafka to manage metadata) arrived as an early-access feature, though it was marked as production-ready on October 3, 2022. Early-access migration from ZooKeeper to KRaft functionality is scheduled for release in Kafka 3.4. Its production-ready version is planned for the Kafka 3.5 release, along with ZooKeeper support deprecation. Finally, the plans are to run without ZooKeeper for all deployments starting with Kafka 4.0.
Kafka without ZooKeeper timeline (source: KIP-833)
Meanwhile, for developers who are open to an alternative, Redpanda is a fully-compatible replacement for Apache Kafka. A key advantage in the way it replaces ZooKeeper is that the quorum servers required by KRaft are not necessary (shown below) which simplifies architecture and makes the environment smaller and easier to manage. It supports all of the Kafka API features and reduces latency by approximately ten times as compared to standard Kafka when deployed on a similar hardware. You can learn more about the Redpanda platform here.

Kafka with ZooKeeper
The setup with ZooKeeper has a separate ZooKeeper cluster that is used by the Kafka cluster to discover members of the Kafka cluster, store a significant part of configurations, and coordinate brokers and data on them. Each broker starts up a controller process, and the first one to register in ZooKeeper becomes an active controller, which makes it eligible to manage the cluster and push the changes to all brokers. Other controllers keep regularly checking ZooKeeper in case the active controller suddenly disappears, in which case the first one to detect the active controller’s absence tries to register and promote itself to an active controller of the cluster.
Kafka without ZooKeeper
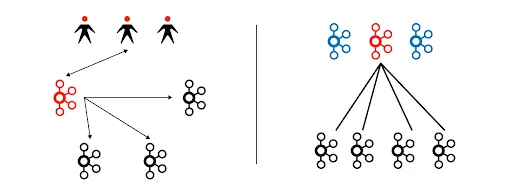
The Kafka cluster setup without ZooKeeper has a special type of server - controller. The controller servers form a cluster quorum. The cluster uses the KRaft algorithm (we leave algorithm theoretical description out of the scope, for more details refer to KRaft documentation or Raft documentation) to choose a leader, which starts to serve requests from other brokers that connect to pull the metadata of the cluster state. The model for brokers has changed: previously, an active controller pushed the changes to brokers, whereas now brokers pull metadata from a leader controller.
The Kafka community implemented a lot of internal changes within its latest releases, of which these are among the most important:
- Kafka cluster scaling limitations have been addressed: Kafka can handle more topics and partitions, and start and restore time were significantly improved. The Kafka controller does not need to read all the metadata from ZooKeeper — each controller has the metadata locally, which saves valuable time bringing the cluster back into operation.
- Knowledge requirements and production setups for one Kafka technology is simpler than using both Kafka and ZooKeeper because each technology requires setting up a system configuration, security, observability, logging, etc. The fewer different technologies, the fewer dependencies and mutual interconnections.
[CTA_MODULE]
Kafka cluster deployment without ZooKeeper
We will deploy a four-node cluster with three controller nodes (server1, server2, and server3) that form a controller quorum and one normal broker (server4) that easily scales from one to N by just adding N broker nodes. We will use an Ubuntu OS, but you may use any other supported distribution you prefer.
For each host, connect and run the following:
1.Install the Java runtime environment, which is required to run Apache Kafka:
sudo apt-get install -y default-jre2.Download and unarchive the package, create a user and data directory, and switch to that user:
wget https://archive.apache.org/dist/kafka/3.3.1/kafka_2.13-3.3.1.tgz
sudo tar -xzvf kafka_2.13-3.3.1.tgz -C /opt
sudo mkdir -p /data/kafka
sudo useradd -m -s /bin/bash kafka
sudo chown kafka -R /opt/kafka_2.13-3.3.1 /data/kafka
sudo su - kafka3.You will find three default KRaft configuration file examples in the unarchived directory. Pay attention to the property process.roles, which defines whether the server will be a controller, broker, or both at the same time. No actions are required in this step.
ls -1 /opt/kafka_2.13-3.3.1/config/kraft/
Output:
broker.properties
controller.properties
README.md
server.properties4.Now, we will generate a unique cluster ID. You will create and copy a universal unique identifier (UUID), which is used in KRaft to uniquely identify the brokers on the same cluster. We will use the UUID value later on. You will also see the UUID value in some command outputs. Proceed as follows:
/opt/kafka_2.13-3.3.1/bin/kafka-storage.sh random-uuid
Output:
jkUlhzQmQkic54LMxrB1oA5.Now we are ready to create a cluster’s quorum, consisting of server1, server2, and server3. For each server, choose a unique (within the cluster) node ID value. For simplicity, we will use 1 for server1, 2 for server2, and 3 for server3. Set the corresponding ID value to CURRENT_SERVER_INDEX. Also remember to update the cluster UUID to yours. The following commands will update the controller.property file and start the Kafka daemon:
export CURRENT_SERVER_INDEX=1
export CLUSTER_UUID=jkUlhzQmQkic54LMxrB1oA
sed -i "s#node.id=.*#node.id=${CURRENT_SERVER_INDEX}#g" controller.properties
sed -i "s#controller.quorum.voters=.*#controller.quorum.voters=1@server1:9093,2@server2:9093,3@server3:9093#g" controller.properties
sed -i "s#log.dirs=.*#log.dirs=/data/kafka#g" controller.properties
/opt/kafka_2.13-3.3.1/bin/kafka-storage.sh format -t ${CLUSTER_UUID}-c /opt/kafka_2.13-3.3.1/config/kraft/controller.properties
/opt/kafka_2.13-3.3.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.13-3.3.1/config/kraft/controller.propertiesNotice that you have already used the kafka-storage utility to generate a UUID and format the data directory for the new KRaft format. After executing kafka-server-start.sh, you will get a running Kafka controller service.
6.Repeat this operation for server2 and server3, with the corresponding IDs of 2 and 3.
7.Finally, we can create a normal broker by running the following commands at server4. We will set the ID to 4 for it:
export CURRENT_SERVER_INDEX=4
sed -i "s#node.id=.*#node.id=${CURRENT_SERVER_INDEX}#g" broker.properties
sed -i "s#controller.quorum.voters=.*#controller.quorum.voters=1@server1:9093,2@server2:9093,3@server3:9093#g" broker.properties
sed -i "s#listeners=.*#listeners=PLAINTEXT://server${CURRENT_SERVER_INDEX}:9092#g" broker.properties
sed -i "s#log.dirs=.*#log.dirs=/data/kafka#g" broker.properties
/opt/kafka_2.13-3.3.1/bin/kafka-storage.sh format -t jkUlhzQmQkic54LMxrB1oA -c /opt/kafka_2.13-3.3.1/config/kraft/broker.properties
/opt/kafka_2.13-3.3.1/bin/kafka-server-start.sh -daemon /opt/kafka_2.13-3.3.1/config/kraft/broker.propertiesSimilar to the previous step, we get a running kafka broker daemon.
8.To populate some metadata, let’s create a topic called test1:
/opt/kafka_2.13-3.3.1/bin/kafka-topics.sh --bootstrap-server
server4:9092 --create --topic test1
/opt/kafka_2.13-3.3.1/bin/kafka-topics.sh --bootstrap-server
server4:9092 –list
Output:
test1
[CTA_MODULE]
KRaft cluster internals
Metadata storage
In the previous section, we got a running Kafka cluster without ZooKeeper that had one topic. We will now check how the metadata is stored from two different perspectives: metadata log segments and utility tools.
Let’s check what is inside the data directory of each server. Controller nodes contain the following in the storage director
ls -1 /data/kafka/
Output:
bootstrap.checkpoint
__cluster_metadata-0
meta.propertiesThe file bootstrap.checkpoints contains checkpoint markers. The meta.properties file has information about the current server, version, and cluster ID. We are most interested in the files inside the directory __cluster_metadata-0, which accumulates all the metadata changes of the cluster:
ls -1 __cluster_metadata-0/
Output:
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000000000159.snapshot
00000000000000000288.snapshot
00000000000000000459.snapshot
00000000000000000630.snapshot
00000000000000000827.snapshot
00000000000000001032.snapshot
00000000000000001257.snapshot
00000000000000001419.snapshot
00000000000000001585.snapshot
leader-epoch-checkpoint
partition.metadata
quorum-stateLet’s check the files. quorum-state contains information on the current leader, the leader epoch sequence number and offset, and the list of controller nodes:
cat quorum-state
Output:
{"clusterId":"","leaderId":1,"leaderEpoch":137,"votedId":1,"appliedOffset":0,"currentVoters":[{"voterId":1},{"voterId":2},{"voterId":3}],"data_version":0}partition.metadata contains nothing special, just a version and topic ID
cat partition.metadata
Output:
version: 0
topic_id: AAAAAAAAAAAAAAAAAAAAAQFinally we get to the most interesting part, the log segment files that may be explored in two kafka utilities:
- kafka-dump-log with flag --cluster-metadata-decoder
- kafka-metadata-shell
kafka-dump-log
We are going to run the kafka-dump-log command to decode cluster metadata. The output contains different event types and, in our example, we will mention three:
- Topic creation
- Topic’s partition creation
- NoOp
If you check the output, you will most likely notice that there are lots of NoOp events, which are used for advancement of the Log End Offset (LEO) and High-Watermark (HW). They do not change the controller or broker state when applied and neither is included in metadata snapshots.
Another type is TOPIC_RECORD, which changes the state by adding a new topic to the cluster. You may see the name and ID of the topic we created earlier.
TOPIC_RECORD is followed by one PARTITION_RECORD (since the default number of partitions is one). The record changes the broker state by adding a partition of the topic along with the new partition state: its leader replicas, brokers where the replica is placed, and other metadata like initial leader epoch and partition epoch. In case of quorum issues, you can dump the log file and search the cluster status changes for each node. Output examples are below:
kafka-dump-log.sh --cluster-metadata-decoder --files
00000000000000000000.log --print-data-log
Output:
#Topic creation:
| offset: 1137 CreateTime: 1666637387916 keySize: -1 valueSize: 26 sequence: -1 headerKeys: [] payload:
{"type":"TOPIC_RECORD","version":0,"data":{"name":"test1","topicId":"v2PBI5LYSBKXvb-8fw8pKQ"}}
#Topic’s partition creation:
| offset: 1138 CreateTime: 1666637387916 keySize: -1 valueSize: 48 sequence: -1 headerKeys: [] payload:
{"type":"PARTITION_RECORD","version":0,"data":{"partitionId":0,"topicId":"v2PBI5LYSBKXvb-8fw8pKQ","replicas":[4],"isr":[4],"removingReplicas":[],"addingReplicas":[],"leader":4,"leaderEpoch":0,"partitionEpoch":0}}
#NoOp heartbeat:
| offset: 1139 CreateTime: 1666637388203 keySize: -1 valueSize: 4 sequence: -1 headerKeys: [] payload:
{"type":"NO_OP_RECORD","version":0,"data":{}}kafka-metadata-shell
The kafka-metadata-shell utility is another approach to explore the log files. Let’s choose a log file and take a brief look at the internal structure:
kafka-metadata-shell.sh --snapshot /data/kafka/__cluster_metadata-0/00000000000000000000.log
>> ls /
brokers features local metadataQuorum topicIds topics
As you can see, we got to a shell environment. You can check the available commands by running the help command:
>>
cat Show the contents of metadata nodes.
cd Set the current working directory.
exit Exit the metadata shell.
find Search for nodes in the directory hierarchy.
help Display this help message.
history Print command history.
ls List metadata nodes.
man Show the help text for a specific command.
pwd Print the current working directory.
The layout is intuitively easy to understand, especially if you have already had a chance to become familiar with the data layout of ZooKeeper.
The topics are placed in /topics. Deeper in the directory, you may find topic names with underlying partitions metadata. For example:
>> ls /topics
test1
>> ls /topics/test1
0 id name
>> ls /topics/test1/name
name
>> cat /topics/test1/name
test1
>> cat /topics/test1/id
v2PBI5LYSBKXvb-8fw8pKQ
>> cat /topics/test1/0/data
{
"partitionId" : 0,
"topicId" : "v2PBI5LYSBKXvb-8fw8pKQ",
"replicas" : [ 4 ],
"isr" : [ 4 ],
"removingReplicas" : [ ],
"addingReplicas" : [ ],
"leader" : 4,
"leaderEpoch" : 3,
"partitionEpoch" : 3
}
You may also get the topics IDs by checking the /topicIds directory
>> ls /topicIds/
v2PBI5LYSBKXvb-8fw8pKQhe list of brokers can be found in the /brokers directory. Each broker has its directory and its state, metadata, and some registration properties inside
>> cat /brokers/4/registration
RegisterBrokerRecord(brokerId=4, incarnationId=aUuLVzc7QsmV5hJKiOAdlg, brokerEpoch=4438, endPoints=[BrokerEndpoint(name='PLAINTEXT', host='server4', port=9092, securityProtocol=0)], features=[BrokerFeature(name='metadata.version', minSupportedVersion=1, maxSupportedVersion=7)], rack=null, fenced=true, inControlledShutdown=false)
>> cat /brokers/4/isFenced
false
>> cat /brokers/4/inControlledShutdown
true
One more directory is /features, which currently covers the protocol version
>> cat /features/metadata.version
{
"name" : "metadata.version",
"featureLevel" : 7
}
Quorum synchronization metadata is stored in /metadataQuorum. There you can find the offset and leader information:
>> cat /metadataQuorum/offset
18609
>> cat /metadataQuorum/leader
LeaderAndEpoch(leaderId=OptionalInt[2], epoch=138)In the directory /local, you can check the Kafka version and source code commit ID:
>> cat /local/commitId
e23c59d00e687ff5
>> cat /local/version
3.3.1afka-metadata-quorum
Let’s check another utility, kafka-metadata-quorum, which has two flags: --status and --replicas. The following example prints out the status of the cluster:
kafka-metadata-quorum.sh --bootstrap-server server4:9092 describe --status
Output:
ClusterId: jkUlhzQmQkic54LMxrB1oA
LeaderId: 2
LeaderEpoch: 138
HighWatermark: 9457
MaxFollowerLag: 9458
MaxFollowerLagTimeMs: -1
CurrentVoters: [1,2,3]
CurrentObservers: [4]
Here you can find the cluster ID, current leader’s ID, leader epoch counter, high-watermark value, maximal follower, follower lag time, and a list of controller quorum members and usual brokers.
To show more diverse output for –replication option, let’s stop one of the controllers (NodeId=1) and see the output:
kafka-metadata-quorum.sh --bootstrap-server server4:9092 describe --replication
kafka-metadata-quorum.sh --bootstrap-server server4:9092 describe --replication
Output:
NodeId LogEndOffset Lag LastFetchTimestamp LastCaughtUpTimestamp Status
2 10486 0 1666642071929 1666642071929 Leader
1 9952 534 1666641804786 1666641804285 Follower
3 10486 0 1666642071608 1666642071608 Follower
4 10486 0 1666642071609 1666642071609 ObserverYou can see the status of the nodes: controllers are in the state leader or follower. The usual broker is in the state observer, which does not form part of the quorum, though the observer has a local copy of the metadata, too. There is one more possible state, a candidate, which is an intermediary state for promotion from follower to leader. You can read more about it in KIP-595.
Takeaways
- Pay attention to the currently missing features (limitations) of current KRaft controllers (more details here).
- If you must set up a new production cluster that is not super-critical, it might be worth considering a Kafka 3.3+ setup without ZooKeeper to reduce the necessity of migrating later on.
- However, remember that KRaft was marked production-ready recently, in Kafka version 3.3, so there are few battle- and time-tested production deployments yet.
- If you are running up-to-date production environments, try to raise a test environment without ZooKeeper to start gaining operational experience with KRaft.
[CTA_MODULE]
Conclusion
The Kafka community has worked arduously to break up with ZooKeeper. The key functionality works and is ready to be used for fresh deployments. In the coming months and years, we will see production-ready migration utilities, and massive migration will start. If you are keen to keep on track and regularly roll out updates to your environments, it is a good time to set up a test KRaft cluster to get a feel for the technology. Meanwhile, a fully-compatible and higher-performing replacement for Kafka exists in the form of Redpanda, which doesn’t require Zookeeper or dedicated KRaft controller servers, and you can learn about its features here.
[CTA_MODULE]