

Event streaming systems—Must-have features and why you need them











Event streaming systems
Event streaming systems have become increasingly popular and are essential to delivering business services like real-time analytics, fraud detection, and IoT. They have their roots in service-oriented architecture (i.e., microservices) that began to gain popularity in the 90s as an approach to breaking down monolith software and decoupling systems.
Service-oriented architecture evolved into event-driven architecture that focused on the production and consumption of “events”—asynchronous, atomic messages containing updates or state changes broadcast from a service without knowledge of which downstream services might consume them. Message brokers and event buses emerged to support the asynchronous delivery of these events.
Event streaming systems were developed in the last decade to cope with the volume and velocity of Big Data demands. These systems process data in real time as it flows through the system, providing significant advancements in response times, processing ability, scalability, observability, error handling, and message guarantees.
This article looks at the crucial features of modern event streaming systems and the essential factors you should consider when choosing one that suits your needs.
Summary of key features of event streaming systems
You must consider the following factors when selecting an event streaming system.
The rest of this article elaborates on these features in detail. We also look at how Redpanda, one of the top event streaming systems in the market today, demonstrates these capabilities.
Data throughput
Throughput is the rate at which the event streaming system can handle messages. Systems should be scalable to cater to higher data rates as requirements increase. The efficiency with which they can scale helps to reduce ongoing costs.
Event streaming systems achieve higher rates by spreading data across different servers (brokers) using partitioning, allowing processing to be divided into manageable chunks.
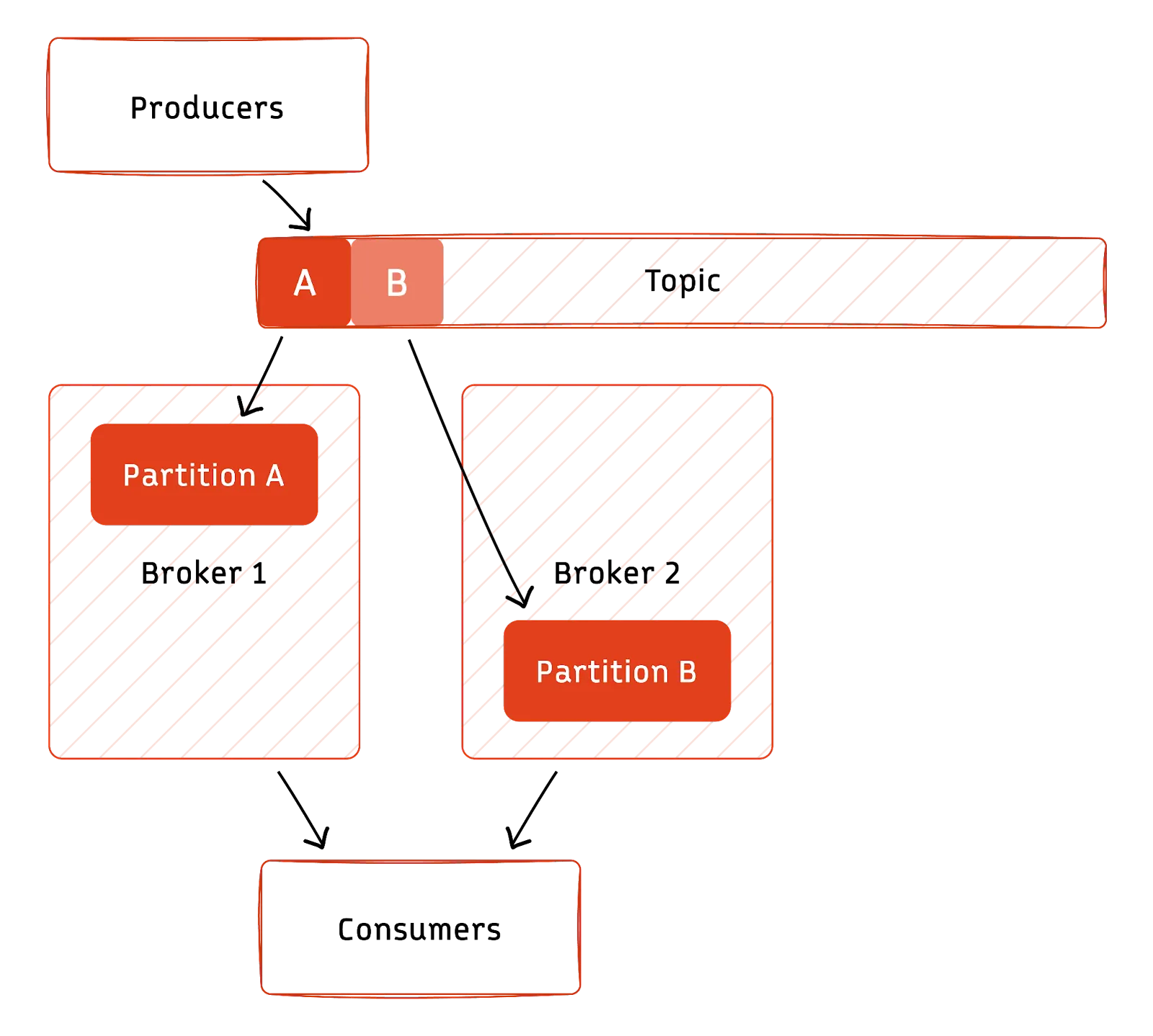
In the diagram above:
- Messages are separated by a partitioning key (if provided, otherwise distributed evenly across partitions per partitioner class) and written concurrently to the partition leader broker.
- Consumers read messages from partitions on different brokers, by default, they read from the partition leader but can optionally be read from followers if the “follower fetching” feature is used.
You can increase the number of partitions and brokers the topic spreads over as the throughput demand increases. For example, if you would like to reduce the consumer lag you can increase the number of partitions, which allows for more consumers to read from the topic in parallel.
High-performing event streaming systems handle high throughput with a minimum number of brokers. For example, the latest benchmarking tests show Redpanda can manage more than 1GB/sec throughput with only three brokers. In contrast, its closest competitor, Apache Kafka® has a sizing rule of thumb of 25 MB/s per broker to achieve the same level of performance.
Redpanda has no sizing constraints and performs at a staggering 70x faster than Kafka with half the hardware (three brokers versus six brokers).
[CTA_MODULE]
Fault tolerance
Fault tolerance is the capability of a system to continue operating when infrastructure components fail. Systems should cope with unexpected environmental issues to ensure the continuity of the service.
In event streaming systems, partitions are replicated by default across multiple cluster nodes to provide redundancy, ensuring that the system can keep running in case of underlying failures:
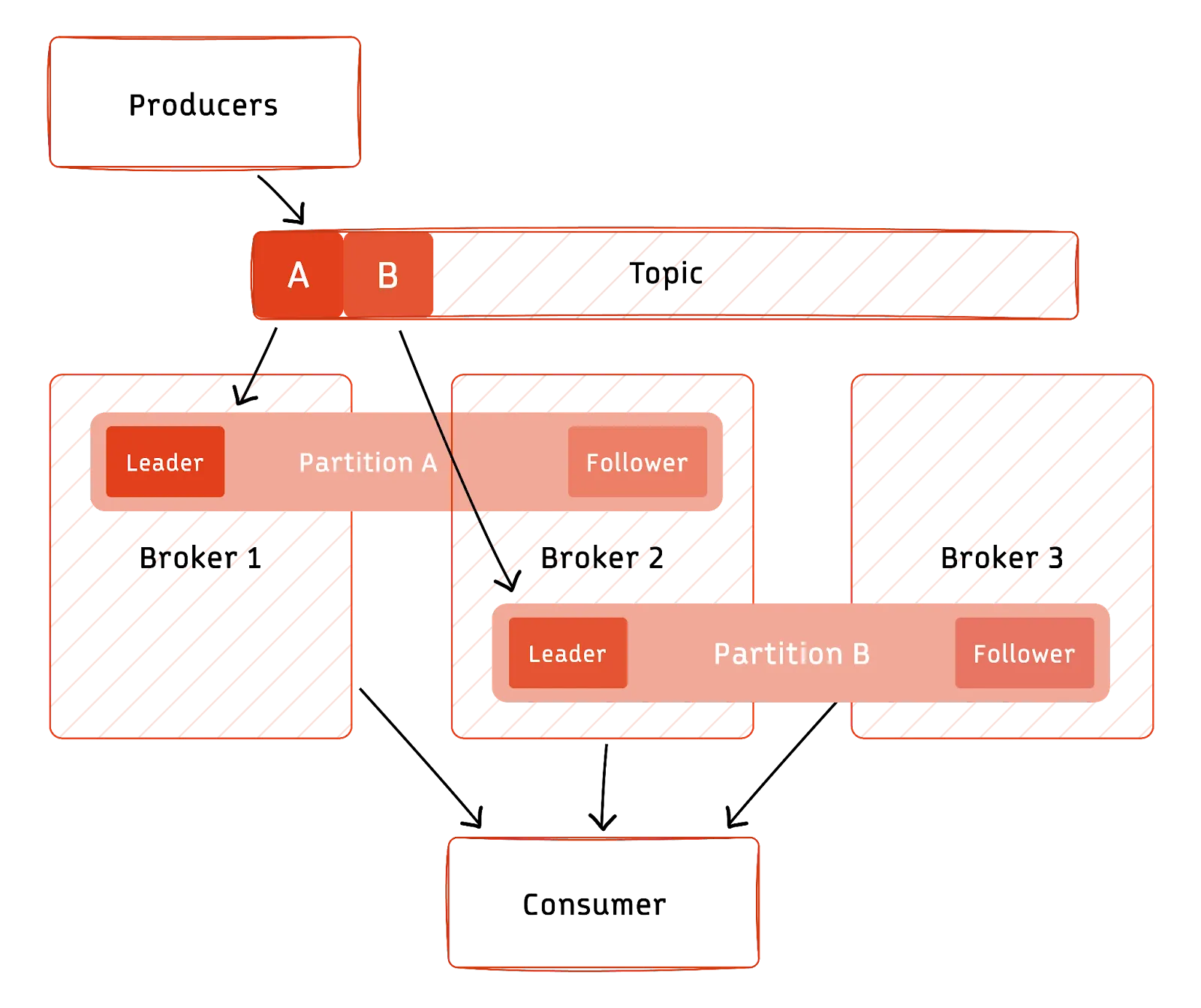
The leader broker processes read and write requests, and messages are replicated across all replicas assigned to that partition.
If a broker containing a partition leader fails, another can take its place using the replicated data.

Redpanda provides configurable, strong guarantees for fault tolerance and implements the Raft consensus protocol to ensure data consistency across multiple nodes, even during reconfiguration. When a topic is created, Redpanda evenly distributes its partitions by sequentially allocating them to the cluster broker with the least number of partitions.
Redpanda also automatically provides leadership balancing and partition rebalancing for existing topics when brokers are added or decommissioned. Ongoing data and leadership re-distribution (“re-balancing”) across nodes enables clusters to self-manage and self-heal, preventing performance hotspots without administrative overheads.
Durability and reliability
Reliability is the ability of event streaming systems to operate consistently over time. Durability guarantees that a committed transaction will not be lost. There are several areas where these factors are essential, and you must consider what your applications will expect of the system and what configuration will be required to maintain business-level requirements.
System reliability
Messages must be written to persistent storage to survive complete system failure. Clean shutdown should be supported for maintenance activities. In Kafka, “unclean leader election” may be required for recovery from a significant failure if availability is more important than data integrity.
Redpanda is designed to be deployed in a cluster with the necessary cluster characteristics to achieve reliability matching your requirements. For example, you can configure clusters with nodes in different data centers or different regions.
Client reliability
Consumer redundancy should be supported, allowing multiple consumers to collect messages for the same purpose. Message retention should match your requirements for clients to be offline for periods or to replay events if clients experience failures after committing the receipt of the message.
Capabilities such as log compaction can allow clients to access the last state of a given message “key”, even after retention policies have flushed all messages. Log compaction is a background process that “cleans up” log segments by removing older records with the same key as newer ones.
By doing so, the log retains only the most recent state of each record, reducing the storage footprint and ensuring the availability of the latest data. There is an adjacent cleanup policy called “compact+delete” that allows for messages that have been in the topic over a defined retention period to be deleted in addition to compacting by key.
Message delivery guarantees
The system should provide specific guarantees for applications to produce outcomes consistent with their goals. These include:
- Message ordering, where messages are stored in sequential order by partition, in the order they were produced and are also consumed in that same order;
- Message acknowledgment, where a configurable number of replicas need to be synchronized before a message is acknowledged as received;
- Exactly once processing, such as idempotence on the producing side and Exactly Once on the consuming side, which ensures there will be no duplication of messages as perceived by the client application.
In Kafka (and Redpanda), the protocol on the consumer cannot be guaranteed to be consumed only once. This is a key difference in event streaming systems vs message queue platforms, so Kafka API-based consumers must be responsible for ensuring they can handle duplicates themselves. There are many methodologies to do this.
Redpanda provides a comprehensive set of configurations enabling the system to match your message durability requirements.
[CTA_MODULE]
Scalability
As your data scales, you need to be able to scale your event streaming system quickly to cope with the demand. On the platform side, adding capacity should be a simple matter of adding more brokers without adding new control structures or complicated configurations, and it should not result in any downtime.
On the client application services side of your event streaming system, you can and should rely on efficient scaling and autoscaling of your applications, often done in Kubernetes, to name one.
For example, if you are consuming data as a Kafka consumer and the end result has lagged compared to the rate at which you produce messages, you should detect that lag is rising too quickly and spin up as many additional consumer instances as you have partitions.
You should find a performant solution for your use case and ensure that it will be linearly and horizontally scalable. When considering hardware to run your workloads, compatibility with the chosen platform is critical when dealing with smaller IoT or edge devices with minimal resource requirements. For example, if you’ve chosen the ARM architecture to run your edge workloads,
Finally, you should ensure that you have an effective way of managing your growing data. Features such as Redpanda’s Tiered Storage, where older data can be offloaded to object storage, allow you to retain more data for more extended periods without the expense of operating the entire data store at the highest performance rates.
Monitoring and observability
Good visibility of system status, performance, and potential issues helps you manage operational maintenance, identify areas for optimization, spot bottlenecks early, and ensure system availability.
Your event streaming systems should expose detailed, granular performance metrics and component status visibility data using standards that you can easily integrate into observability tools like Prometheus, Grafana, Data Dog, New Relic, and others.
You should configure alerts and dashboards early and use these to assess the effectiveness and performance of the system. It will make scaling easier if monitoring and observability functionality is automatically onboarded with new broker nodes.
Redpanda provides monitoring endpoints for each broker as standard, and example dashboards and alerting rules can allow you to get observability up and running quickly.
Security
Data security and restricting unauthorized access to data are as essential in event streaming systems as in traditional RDBMS systems. Good data security supports business-level requirements and can prevent human error, such as test data being sent into production environments.
Each user or system client should be authenticated, its access authorized, and data may need to be encrypted in transit. Systems that integrate easily with external authentication systems like OAuth and OIDC reduce the operational burden of managing access, and providing appropriate access controls ensures that clients only perform the operations they should.
An event streaming system with access control lists (ACLs) enables you to implement your security requirements and maintain appropriate data governance in compliance with your organizational policies. For example, Redpanda provides out-of-the-box configurations for several different authentication mechanisms, and you can easily manage ACLs through its console and on the command line or through the Redpanda Console user interface.
APIs and integrations
Event streaming systems supporting a comprehensive set of languages enable consumers to use the tools they are most comfortable with, lowering the bar for development and testing. If integrations to other platforms are readily available, these can be used to deploy functionality more rapidly and reduce the maintenance overhead of customized software.
It’s worth considering what systems you need to integrate with now and what might be required in the future. The more ‘off the shelf’ features are available, the easier it will be to respond to new demands. For example, Redpanda is fully Kafka API compatible and supports interacting with all the readily available client libraries for various integrations.
Cost-effectiveness
Regardless of the level to which the previous requirements are important to you, cost should be considered early on, including how it will increase with increased volume.
Significant costs for event streaming systems are in the form of:
- Compute costs
- Storage costs
- Networking costs
- Support and maintenance costs.
The system's architectural complexity can significantly impact computing, networking, and support costs. Deploying cluster management, schema registry, and proxy services increases the computing requirements and requires specialist skills and cost support time.
Broker efficiency also has a direct correlation to costs as requirements scale. Your brokers should be well-tuned and efficient to ensure you can maximize your allocated hardware usage.
Storage costs depend on your data volume and retention requirements but can be optimized if the system supports different compression formats and tiered storage. Operational costs are incurred for maintenance, upgrades, and administrative activities. The system should be simple to manage and provide well-supported maintenance procedures, automated or otherwise. A managed service can be cost-effective, especially considering support and maintenance costs.
Redpanda has been demonstrated to be 6x more cost-effective than Kafka, and Redpanda Cloud now has support for deployment on ARM processor-based instances, improving cost-efficiency by an additional 50%.
[CTA_MODULE]
Conclusion
As event processing technology has evolved, it has become a standard expectation in the IT industry to have high-volume, low-latency event streaming systems. When choosing one, you must consider your business requirements and how well the system can meet your current and future needs—using a modern implementation, such as Redpanda, makes a considerable difference in the ease of use and efficiency of your deployment.
The Redpanda team is also looking beyond the current standards to the next stage in the evolution of event streaming platforms. For example, the newly released Wasm-based Data Transforms adds in-broker stream processing capabilities that allow you to perform stateless transformation functions like routing, filtering, data transformation, and filters in a common input -> output topic pattern as the data flows through the system—without having to “ping pong” outside the cluster.
Interested in trying it for yourself? Take Redpanda for a free spin! Check the documentation and browse the Redpanda blog for how to easily integrate Redpanda with your streaming data stack. If you get stuck or want to chat with the team, join the Redpanda Community on Slack.
[CTA_MODULE]